Databricks is a unified big data processing and analytics cloud platform that transforms and processes enormous volumes of data. Apache Spark is the building block of Databricks, an in-memory analytics engine for big data and machine learning. In this article, we will see how to call a notebook from another notebook in Databricks and how to manage the execution context of a notebook.
What is Databricks notebook and execution context?
Notebooks in Databricks are used to write spark code to process and transform data. Notebooks support Python, Scala, SQL, and R languages.
Whenever we execute a notebook in Databricks, it attaches a cluster (computation resource) to it and creates an execution context.
Pre-requisites:
If you want to run Databricks notebook inside another notebook, you would need the following:
1. Databricks service in Azure, GCP, or AWS cloud.
2. A Databricks cluster.
3. A basic understanding of Databricks and how to create notebooks.
Methods to call a notebook from another notebook in Databricks
There are two methods to run a Databricks notebook inside another Databricks notebook.
1. Using the %run command
%run command invokes the notebook in the same notebook context, meaning any variable or function declared in the parent notebook can be used in the child notebook.
The sample command would look like the one below.
%run [notebook path] $paramter1="Value1" $paramterN="valueN"

This method is suitable for defining a notebook with all the constant variables or a centralized shared function library. And you want to refer to them in the calling or child notebook.
What if we need to execute the child’s notebook in a different notebook context? The following method describes how to achieve this.

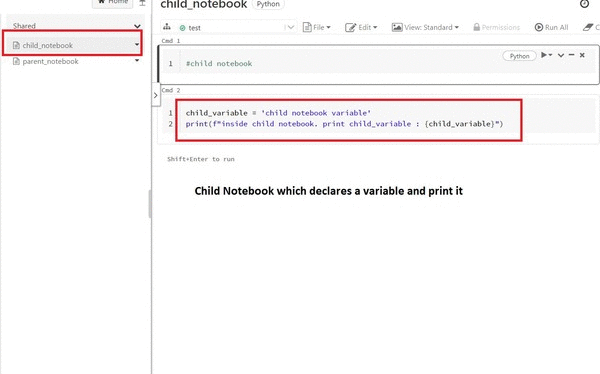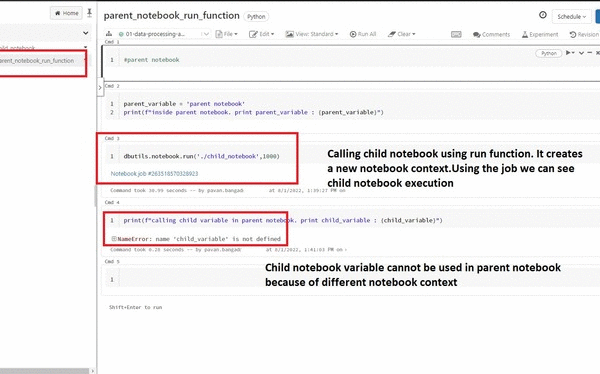
2. Using the dbutils.notebook.run() function
This function will run the notebook in a new notebook context.
The syntax of dbutils.notebook function is:
dbutils.notebook.run(notebookpath, timeout_in_seconds, parameters)
Here,
Notebook_path -> path of the target notebook.
Timeout_in_seconds – > the notebook will throw an exception if it is not completed in the specified time.
parameters – > Used to send parameters to child notebook. Parameters should be specified in JSON format.
e.g. {‘paramter1’: ‘value1’, ‘paramter2’: ‘value2’}
We can call the N numbers of the notebook by calling this function in the parent notebook
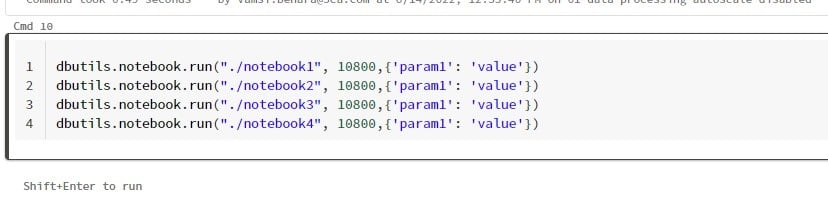
This will run all the notebooks sequentially.
Run Databricks notebooks in parallel
You can use the python library to run multiple Databricks notebooks in parallel. This library helps create multiple threads that run notebooks in parallel.
Import the library as follows:
from concurrent.futures import ThreadPoolExecutor
You can read more about ThreadPoolExecutor here. And here is a sample code that code explorer already wrote for running the notebook in parallel.
Attaching the same notebook used in this blog:
Pro tips:
1. We can use Azure data factory for running notebooks in parallel. Refer to this post to learn more.
2. Jobs created using the dbutils.notebook API must complete in within 30 days.
3. We can only pass string parameters to the child notebook with the methods described in this article, and objects are not allowed.
4. Databricks provide a free community version where you can learn and explore Databricks. You can sign up here.
See more
Pavan Bangad
9+ years of experience in building data warehouse and big data application.
Helping customers in their digital transformation journey in cloud.
Passionate about data engineering.